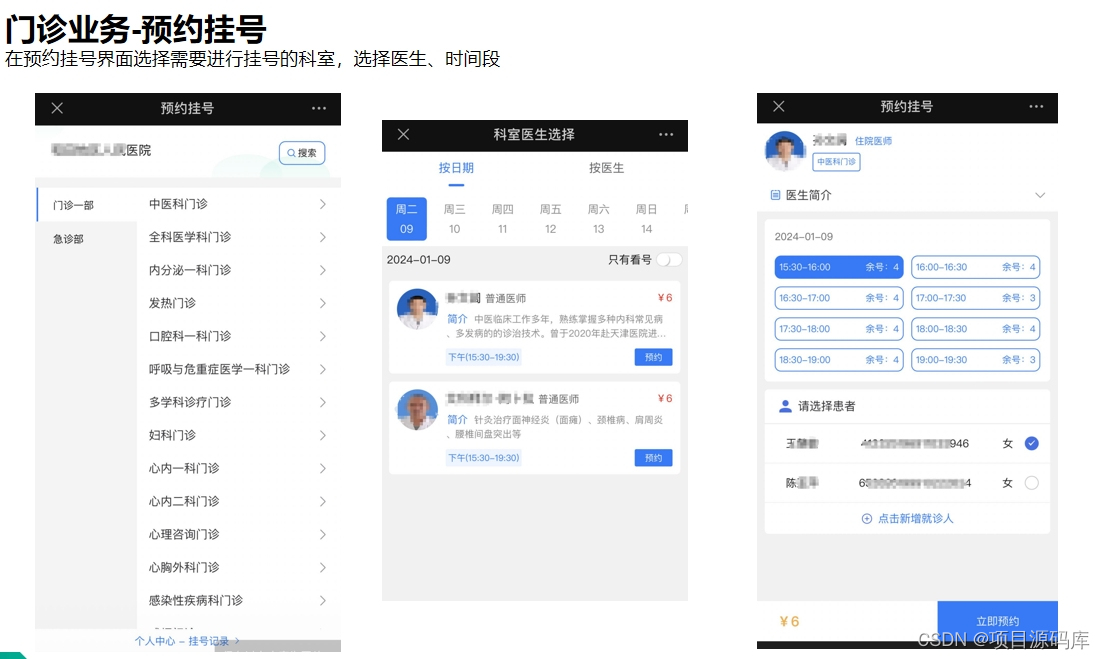
获取最新的CVE信息
GitHub - password123456/cve-collector: Simple Latest CVE Collector Written in Python
__author__ = 'https://github.com/password123456/'
__date__ = '2024.02.27'
__version__ = '1.0.4'
__status__ = 'Production'
import os
import sys
import re
import requests
import hashlib
from datetime import datetime
import time
from bs4 import BeautifulSoup
class Bcolors:
Black = '\033[30m'
Red = '\033[31m'
Green = '\033[32m'
Yellow = '\033[33m'
Blue = '\033[34m'
Magenta = '\033[35m'
Cyan = '\033[36m'
White = '\033[37m'
Endc = '\033[0m'
BOLD = '\033[1m'
UNDERLINE = '\033[4m'
def sha1_hash(string):
return hashlib.sha1(string.encode()).hexdigest()
def is_valid_cve_id_year(cve_id):
cve_id_year = re.findall(r"\d{4}", cve_id)[0]
current_year = datetime.today().strftime("%Y")
# Throw away cve-feed that published more than 1 years ago before
if int(current_year) - int(cve_id_year) >= 1:
return False
else:
return True
def feeds_exists_in_db(feed_db, _hash_to_check, _id_to_check):
try:
if os.path.exists(feed_db):
mode = 'r'
else:
mode = 'w'
n = 0
with open(feed_db, mode) as database:
for line in database:
if not len(line.strip()) == 0:
n += 1
hash_in_db = line.split('|')[2].replace('\n', '')
id_in_db = str(line.split('|')[3].replace('\n', ''))
if str(_id_to_check) == str(id_in_db):
return True
else:
if str(_hash_to_check) == str(hash_in_db):
return True
return False
except Exception as error:
print(f'{Bcolors.Yellow}- ::Exception:: Func:[{feeds_exists_in_db.__name__}] '
f'Line:[{sys.exc_info()[-1].tb_lineno}] [{type(error).__name__}] {error}{Bcolors.Endc}', flush=True)
def fetch_latest_cve_entries(feed_db, feed_url):
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 '
'(KHTML, like Gecko) Chrome/117.0.0.0 Safari/537.36'}
r = requests.get(feed_url, headers=headers, verify=True)
if r.status_code == 200:
body = r.text
soup = BeautifulSoup(body, 'html.parser')
search_results_div = soup.find('div', {'id': 'searchresults'})
if search_results_div:
cve_info_divs = search_results_div.find_all('div', {'data-tsvfield': 'cveinfo'})
if not cve_info_divs:
message = (f'{os.path.realpath(__file__)}\n\n'
f'[{fetch_latest_cve_entries.__name__}]\n'
f'>> Failed to parse HTML elements cve_info_divs <<')
print(f'{Bcolors.Yellow}- {message} {Bcolors.Endc}')
## Send the result to webhook. ##
sys.exit(1)
else:
message = (f'{os.path.realpath(__file__)}\n\n'
f'[{fetch_latest_cve_entries.__name__}]\n'
f'>> Failed to parse HTML elements searchresults_divs <<')
print(f'{Bcolors.Yellow}- {message} {Bcolors.Endc}')
## Send the result to webhook. ##
sys.exit(1)
newest_cve_entries = []
for cve_info_div in cve_info_divs:
try:
cve_id = cve_info_div.find('h3', {'data-tsvfield': 'cveId'}).a.text.strip()
cve_publish_date = cve_info_div.find('div', {'data-tsvfield': 'publishDate'}).text.strip()
cve_link = f"https://www.cvedetails.com{cve_info_div.find('a', href=True)['href']}"
except AttributeError as error:
message = (f'{os.path.realpath(__file__)}\n\n'
f'[{fetch_latest_cve_entries.__name__}]\n{error}\n'
f'>> Failed to parse HTML elements cve_id, cve_publish_date, cve_link <<')
print(f'{Bcolors.Yellow}- {message} {Bcolors.Endc}')
## Send the result to webhook. ##
sys.exit(1)
if not cve_id or not cve_publish_date or not cve_link:
message = (f'{os.path.realpath(__file__)}\n\n'
f'[{fetch_latest_cve_entries.__name__}]\n'
f'>> Failed to parse One or more of cve_id, cve_publish_date, or cve_link is empty <<')
print(f'{Bcolors.Yellow}- {message} {Bcolors.Endc}')
## Send the result to webhook. ##
sys.exit(1)
# Throw away more than 1 years ago before
is_valid_cve_year = is_valid_cve_id_year(cve_id)
if not is_valid_cve_year:
continue
if os.path.exists(feed_db):
hashed_data = sha1_hash(f'{cve_id}_{str(cve_publish_date)}')
if not feeds_exists_in_db(feed_db, hashed_data, cve_id):
newest_cve_entries.append(cve_link)
else:
newest_cve_entries.append(cve_link)
else:
message = (f'{os.path.realpath(__file__)}\n\n'
f'[{fetch_latest_cve_entries.__name__}]\n'
f'- {feed_url}\n- HTTP: {r.status_code}')
print(f'{Bcolors.Yellow}[-] Error: {message} {Bcolors.Endc}')
## Send the result to webhook. ##
sys.exit(1)
return newest_cve_entries
def retrieve_cve_details(feed_db, cve_entries):
if os.path.exists(feed_db):
mode = 'a'
else:
mode = 'w'
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 '
'(KHTML, like Gecko) Chrome/117.0.0.0 Safari/537.36'}
n = 0
cve_content_result = ''
with open(feed_db, mode) as fa:
for cve_link in cve_entries:
time.sleep(5)
r = requests.get(cve_link, headers=headers, verify=True)
if r.status_code == 200:
body = r.text
soup = BeautifulSoup(body, 'html.parser')
cve_content_div = soup.find('div', attrs={'id': 'contentdiv'})
if not cve_content_div:
message = (f'{os.path.realpath(__file__)}\n\n'
f'[{fetch_latest_cve_entries.__name__}]\n\n'
f'>> Failed to parse HTML elements cve_content_div <<')
print(f'{Bcolors.Yellow}- {message} {Bcolors.Endc}')
## Send the result to webhook. ##
sys.exit(1)
try:
cve_id = cve_content_div.find('h1').find('a').text.strip()
description = cve_content_div.find('div', class_='cvedetailssummary-text').text.strip()
published_updated_elements = cve_content_div.find_all('div', class_='d-inline-block')
published_date = published_updated_elements[0].text.strip().replace("Published", "").strip()
updated_date = published_updated_elements[1].text.strip().replace("Updated", "").strip()
base_score_elements = cve_content_div.find_all('td', class_='ps-2')
base_score = base_score_elements[0].find('div', class_='cvssbox').text.strip()
base_severity = base_score_elements[1].text.strip()
cwe_heading = cve_content_div.find('h2', string='CWE ids for ' + cve_id)
if cwe_heading:
cwe_item = cwe_heading.find_next('a')
if cwe_item:
cwe_id = cwe_item.text.strip()
else:
cwe_id = f'Not found CWE ids for {cve_id}'
references_heading = cve_content_div.find('h2', string='References for ' + cve_id)
if references_heading:
references_list = references_heading.find_next('ul', class_='list-group')
if references_list:
reference_links = references_list.find_all('a', class_='ssc-ext-link')
references = [link['href'] for link in reference_links]
else:
references = f'Not found references for {cve_id}'
except AttributeError as error:
message = (f'{os.path.realpath(__file__)}\n\n'
f'[{retrieve_cve_details.__name__}]\n{error}\n\n'
f'>> Failed to parse HTML elements. One or more of the data fields parse error <<')
print(f'{Bcolors.Yellow}- {message} {Bcolors.Endc}')
## Send the result to webhook. ##
sys.exit(1)
if not cve_id or not description or not published_date \
or not updated_date or not base_score or not base_severity:
message = (f'{os.path.realpath(__file__)}\n\n'
f'[{retrieve_cve_details.__name__}]\n\n'
f'>> Failed to parse HTML. One or more of the data fields is empty <<')
print(f'{Bcolors.Yellow}- {message} {Bcolors.Endc}')
## Send the result to webhook. ##
sys.exit(1)
# cut size of the description to 135 bytes
if int(len(str(description))) >= 138:
description = f"{description[:135]}..."
# formatted references list
if references:
i = 0
if isinstance(references, list):
formatted_references = '\n'.join([f'({i + 1}) {ref}' for i, ref in enumerate(references)])
else:
formatted_references = f'({i + 1}) {references}'
# formatted published_date
date_obj = datetime.strptime(published_date, "%Y-%m-%d %H:%M:%S")
formatted_date = date_obj.strftime("%Y-%m-%d")
hashed_data = sha1_hash(f'{cve_id}_{str(formatted_date)}')
if not feeds_exists_in_db(feed_db, hashed_data, cve_id):
n += 1
fa.write(f'{n}|{datetime.now()}|{hashed_data}|{cve_id}|{published_date}'
f'|{base_score}|{base_severity}|{cwe_id}\n')
contents = f'{n}. {cve_id} / CVSS: {base_score} ({base_severity})\n' \
f'- Published: {published_date}\n' \
f'- Updated: {updated_date}\n' \
f'- CWE: {cwe_id}\n\n' \
f'{description}\n' \
f'>> https://www.cve.org/CVERecord?id={cve_id}\n\n' \
f'- Ref.\n{formatted_references}\n\n\n'
cve_content_result += contents
else:
message = (f'{os.path.realpath(__file__)}\n\n'
f'[{retrieve_cve_details.__name__}]\n'
f'- {cve_link}\n- HTTP: {r.status_code}')
print(f'{Bcolors.Yellow}[-] Error: {message} {Bcolors.Endc}')
## Send the result to webhook. ##
sys.exit(1)
return cve_content_result
def main():
home_path = f'{os.getcwd()}'
feed_db = f'{home_path}/feeds.db'
cvss_min_score = 6
feed_url = f'https://www.cvedetails.com/vulnerability-search.php?f=1&cvssscoremin={cvss_min_score}&page=1'
latest_cve_entries = fetch_latest_cve_entries(feed_db, feed_url)
if latest_cve_entries:
cve_details = retrieve_cve_details(feed_db, latest_cve_entries)
if cve_details:
cve_details = f'*{datetime.now()}*\n\n{cve_details}'
print(f'{cve_details}')
## Send the result to webhook. ##
else:
print(f'{Bcolors.Blue}>>> [OK] ({datetime.now()}) No NEW CVE{Bcolors.Endc}')
if __name__ == '__main__':
try:
main()
except KeyboardInterrupt:
sys.exit(0)
except Exception as e:
print(f'{Bcolors.Yellow}- (Exception) Func:[{__name__.__name__}] '
f'Line:[{sys.exc_info()[-1].tb_lineno}] [{type(e).__name__}] {e}{Bcolors.Endc}')